IBM iの文字コードは、長らくEBCDIC が使われてきた。IBM iのデフォルトとも言えるこの文字コードは今も、多くの基幹システムを支えている。その一方、IBM iとオープン系システムの連携や、IBM iをデータベースサーバーとして活用するニーズが高まるなか、IBM iでUnicodeを使用することに注目が集まっている。文字コードの歴史をあらためて振り返りつつ、IBM i環境でのEBCDICの基本とUnicodeの扱い方法を解説する。著者は、日本IBMの三神雅弘氏。3回に分けて掲載します。
第1回 文字コードについて ~その歴史と役割
第2回 IBM iの日本語環境 ~EBCDIC編
第3回 IBM iの日本語環境 ~Unicode編
文字コードについて
その歴史と役割
私たちが情報システムを通してデータを扱う場合、人が認識できるデータ(文字、画像、音声など)を、コンピュータで扱えるデジタルデータ(2進数)へ変換する必要がある。これらのデータのなかでも、文字はデータとしての扱いに加えて、コンピュータへの指示(コマンドやプログラム)としても使用する基本である。
コンピュータで文字を扱うための文字コードは、機種やOSなどによるさまざまなコード体系、各国語の固有の文字を表現するためのコード拡張などに対応してきた結果、多くの文字コードが生まれることになった。
多くの文字コードが存在する、すなわち1つの文字を表現するコードが複数存在することにより、「文字化け」「文字が表示されない」「プログラムが実行されない」といった問題が発生する。このような問題を回避するために、本稿では文字コードについて考えてみたい。
文字コードとは、コンピュータが扱う2進数で文字を処理するために、文字に対して割り当てられた番号(コード)である。文字の集合とその番号の対応関係を示すものとして、文字コードと呼ばれている。
文字コードは、ANSIやISOといった標準化団体によって定義されているが、各国でのコンピュータ利用に向け言語に応じて拡張されてきたため、数多くの文字コードが存在することになった。
文字コードは、「符号化文字集合」と「文字符号化方式」の2つに区別される。
符号化文字集合 (Coded Caracter Set:CCS)は、識別するための番号(コード・ポイント)を割り振られた文字の集合である。前述の文字コードと同様に使用される。代表的な符号化文字集合としては、ASCII、ISO/IEC 646、JIS X 0201などの半角文字の集合、日本語の漢字の集合であるJIX X 0208、各国で使用される文字を共通の文字集合として使用するためのUnicodeなどがある。
一方の文字符号化方式 (Character Encoding Sche
me:CES)は、符号化文字集合の文字に割り当てられたコード・ポイントを、コンピュータ上で実際に使用するバイト列に変換するための定義である。JIX X 0208に対するISO-2022-JP、EUC-JP、Shift_JISや、Unicodeに対するUTF-8、UTF-16、UFT-32が該当する。
以下に、代表的な文字コードについて説明しよう。
ASCII
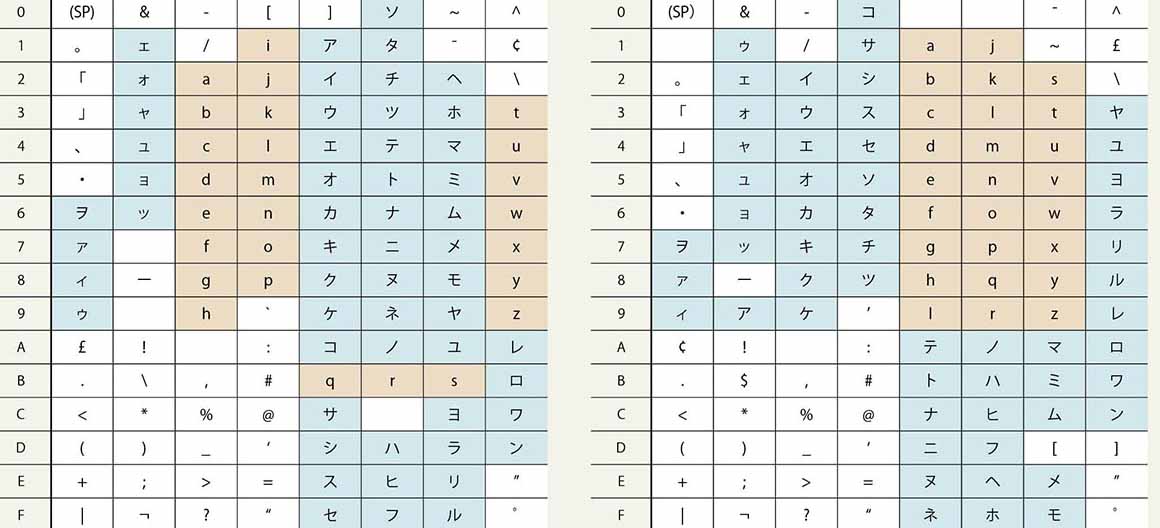
ASCII(American Standard Code for Information Interchange)は、1963年にAmerican Standards Association (ANS、後のANSI)によって定められた7ビットの文字コードである。7ビット(x‘00’からx‘7F’)のコードに、アルファベット、数字、記号と制御コードを割り当てている(図表1)。
たとえば、“A”の16進表記はx‘41’で、“a”の16進表記はx‘61’となる。同じく2進数で表記すると、以下になる。
A:1000001
a:1100001
ASCIIコード表でアルファベットの大文字と小文字を比べると、それぞれの大文字と小文字の下位ビットは同じで、上位ビットは差が2であることがわかる。2進数で表記すると、大文字の6ビット目を1にしたものが小文字となる。これは、大文字と小文字との間の変換は、6ビット目の値を操作するだけで可能ということである。
米国で制定されたASCIIコードでは、定められている文字は英語のアルファベットで、通貨記号は$である。ヨーロッパ各国でコンピュータを利用する場合、ASCIIコードでは必要な文字が含まれていなかったり、通貨記号が異なっていたりするので、各国に対応するための文字コードを用意する必要がある。
そのため、ASCIIコードをベースとする各国語対応の文字コードとして、国際標準化機構(ISO)により7ビットの文字コードISO/IEC 646が定められた。
ただしISO/IEC 646では、ヨーロッパ各国語への対応で設定できる文字の範囲が少なかったため、あまり使用されなかった。そこでヨーロッパ各国は、8ビットに拡張された文字コードISO/IEC 8859を使用することになる。
JIS X 0201
JIS X 0201は、1969年に日本産業規格(JIS)により定められた符号化文字集合である。ISO/IEC 646を拡張した、ラテン文字用図形文字集合と片仮名用図形文字集合の2つの文字集合である。
7ビットおよび8ビットのコードであり、7ビットコードの場合は上位ビットのx‘21’からx‘7E’の領域をラテン文字とカタカナ文字で切り替えて割り当てる。切り替えにはシフトインとシフトアウトを用いる。
8ビットコードの場合は、上位ビットのx‘21’からx‘7E’の領域をラテン文字、x‘A1’からx‘FE’の領域をカタカナ文字で割り当てる。
EBCDIC
EBCDIC (Extended Binary Coded Decimal Interchange Code、拡張二進化十進コード)は、IBMが1964年に発表したメインフレームのSystem/360で使用するために、1963年に定められた8ビットの文字コードである。10進数を4ビットの2進数で表すBCD (Binary-Coded Decimal)を拡張する形で定義された。EBCDICコードは、IBMメインフレームおよびIBM iのようなミッドレンジシステムで使用されている。
IBMは、文字データの表記や処理の一貫性の実現を目的とした文字コードの設計指針となる文字データ表示体系(Character Data Representation Architecture:CDRA)を定義した。
システム内の文字表現は、CDRAによって制御される。CDRAはコード化スキームID、文字セットID、コード・ページID、および追加のエンコード関連情報によって文字を識別する。このCDRAによって文字を識別するために定義されているIDが、CCSID(Coded Character Set IDentifiers:コード化文字セットID)である。
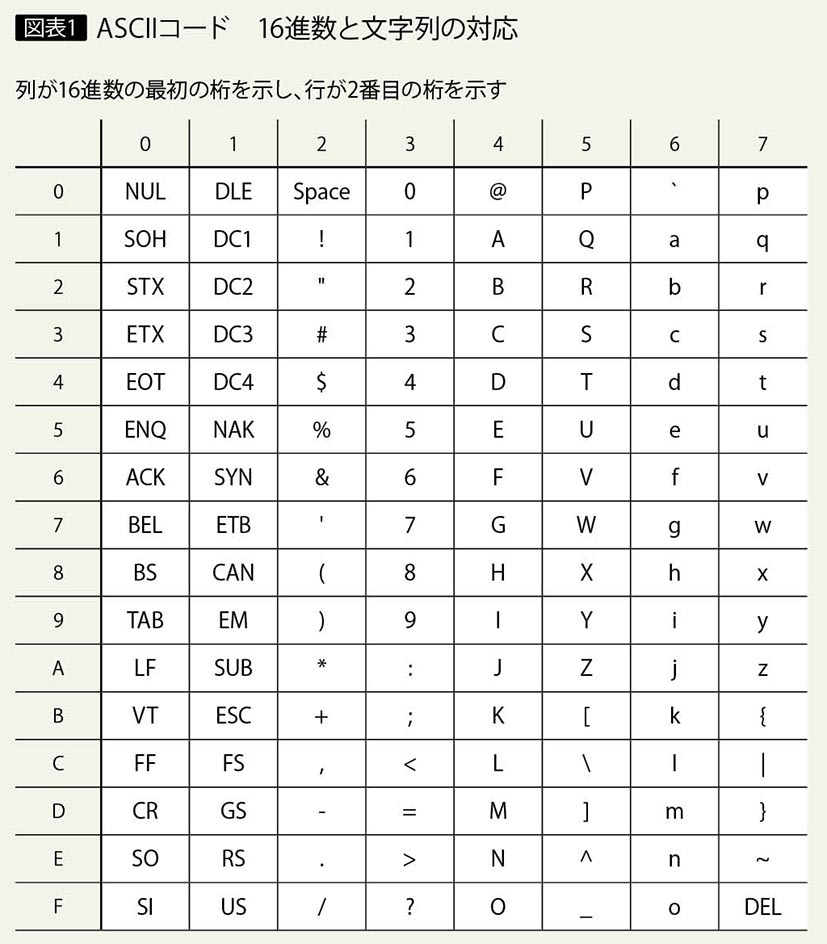
EBCDICは、CCSIDにより識別される符号化方法である。CCSID 37は、コード・ページ37(USA英語)である。
日本語のCCSIDとしては5026、5035、1399などがある。CCSID 5026と5035、1399は、SBCSのコード・ページが異なる。
またコード・ページ290とコード・ページ1027では、カタカナのコード・ポイントが異なる。
コード・ページ290のカタカナは、英語のコード・ページ37の英小文字の部分をカタカナに割り当て、英小文字は異なるコードで割り当てられている。そのため、コード・ページ37のx‘81’の英小文字“a”は、コード・ページ290ではカタカナ“ア”で表されることになる。
またコード・ページ1027では、英小文字のコードはコード・ページ37と同じコードに割り当てられているので、英小文字の扱いは問題ない。しかしコード・ページ290とは英小文字とカタカナの割り当てが異なるため、同じ日本語のコード・ページでもカタカナと英小文字の表記が異なる(図表2)。
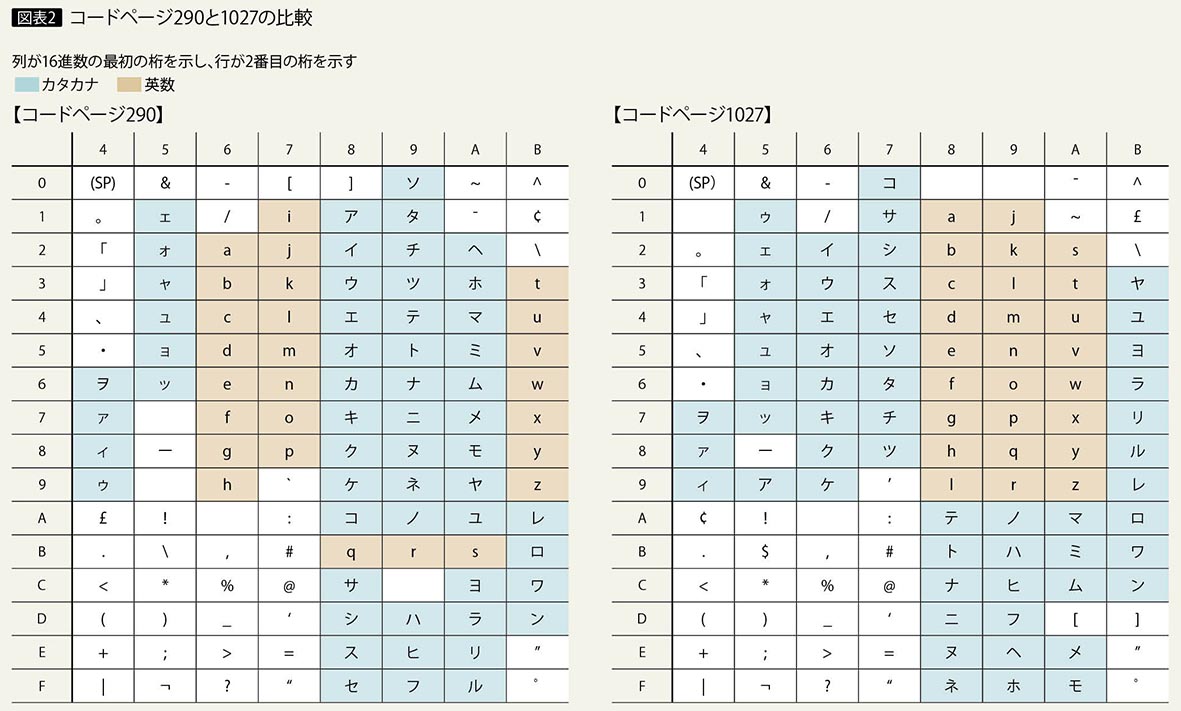
このような英小文字とカタカナの「文字化け」の問題のほかに、コード・ページ290では英小文字、大文字を区別しているプログラムが動作しない問題も発生する。IBM i でJavaやC、C++などを使用する場合には、英小文字のコードが、英語コード・ページ37と同じコード・ページ1027を使用するCCSID 5035やCCSID 1399を指定する必要がある。
Unicode
文字コードは各国あるいは各メーカーがそれぞれ独自に使用するコード体系を定義してきたため、互換性のない数多くの文字コードが存在している。そこで、各国のすべての文字を1つのコード体系で示すために定められたのがUnicodeである。コンピュータ関連企業が参加するユニコードコンソーシアムにより、Unicodeが定められた。
一方、同時期にISOによる国際規格としてISO/IEC 10646の策定が進められていた。そこで同じ目的の規格が複数存在することを避けるため、UnicodeとISO/IEC 10646を統一する作業が行われた。当初4バイトとして定義されていたISO/IEC 10646に、2バイトのUnicodeを基本多言語面(Basic Multilingual Plane :BMP)として取り込む形で、1993年に制定された。
ISO/IEC 10646の規格名称は「Universal Multiple-Octet Coded Character Set (UCS)」で、この規格の文字コードがUCSと呼ばれる。
ISO/IEC 10646は、JISではJIS X0221として制定され、国際符号化文字集合(UCS)と呼ばれる。
Unicodeには100万文字以上のコード・ポイントが用意されており、各国の文字や記号だけではなく、歴史的な古代文字や絵文字なども加えて、現在は約14万文字が割り当てられている(*1)。
*1 Unicode 13.0 Character Code Charts http://www.unicode.org/charts/
Unicodeの最初の128のコード・ポイント(U+00 から U+7E)は、ASCIIと同じ文字コードが割り当てられている。
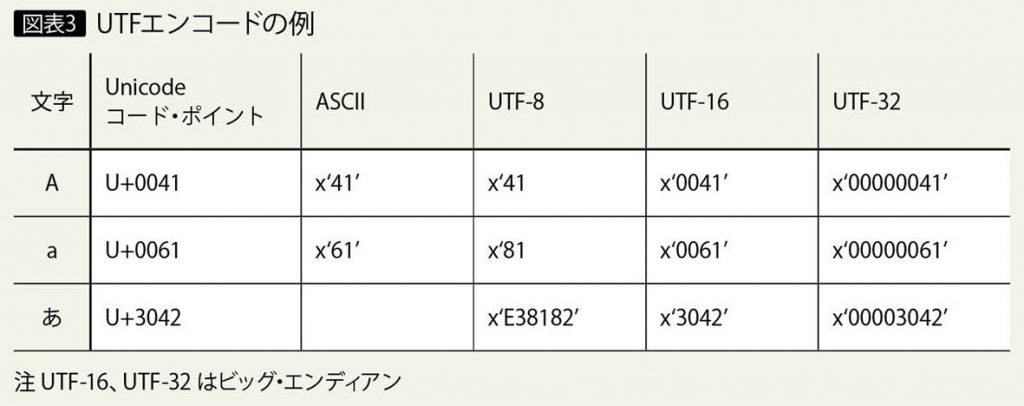
Unicodeは、各文字とそのコード・ポイントを定めた符号化文字集合である。このコード・ポイントを、コンピュータで扱うバイト・コードに変換する文字符号化方式が、UTF(Unicode Transformation Format、あるいはUCS Transformation Format)である。
Unicodeコード・ポイントから UTF のバイト・コードへ変換することを、エンコードと呼ぶ。UTFには、UTF-8、UTF-16、UTF-32のエンコード方式が存在する。
UTF-8
UTF-8は8ビット・コードを基本としており、各文字は1から4バイトでエンコードされる。Unicodeコード・ポイントの最初の128文字は、1バイト・コードでエンコードされ、ASCIIと同じコード・ポイントとなる。
たとえば、文字列「ABC」は、UTF-8ではx‘414243’となり、ASCIIと同じコードで扱われる。ASCIIとの互換性があることから、ネットワークにUnicodeデータであることを知らせなくても、ネットワーク上に8 ビット・データを流せる。
UNIX プラットフォームでは UTF-8 を使用してUni
codeを保管している場合が多く、ほとんどの新しいインターネット標準にデフォルトのエンコード方式として使用されている。
英数字を主に扱う場合はASCIIと同じ1バイトであるが、日本語を扱う場合には3バイトが必要になる。
UTF-16
UTF-16は16ビット・コードを基本としており、各文字は2バイト単位でエンコードされる。Unicodeコード・ポイントの最初の128文字も、2バイト・コードでエンコードされる。
もともとのUnicodeであるUCS-2では、基本多言語面(BMP)と呼ばれる6万5535文字までしか扱えないため、UCS-2を拡張する形で定められたのがUTF-16である。
BMP以外の文字は、サロゲート・ペアと呼ばれる仕組みを用いて示す。通常使用する文字はBMPに含まれているので、サロゲート・ペアを用いるのは稀である。
UTF-32
UTF-32は32ビット・コードを基本としており、各文字は4バイトでエンコードされる。UTF-32は、UCS-4と同じである。すべての文字で常に4バイトを使用するため、多くのストレージが必要となる。そのため、あまり使用されていない。図表3に、UTFエンコードの例を示す。
バイト・オーダー
UTF-16やUTF-32は、1文字のコードを複数バイトで示している。このようなマルチ・バイトのデータでは、バイト配列の順序を定めておく必要がある。この規則をバイト・オーダーと呼び、ビッグ・エンディアンとリトル・エンディアンの2つがある(図表4)。

ビッグ・エンディアン
ビッグ・エンディアンは、最上位のバイトから並べるバイト・オーダーである。たとえば、ひらがなの「あ」のコード・ポイントU+3204は、UTF-16のビッグ・エンディアンでは30 42、UTF-32では 00 00 30 42の順になる。
リトル・エンディアン
リトル・エンディアンは、最下位のバイトから並べるバイト・オーダーである。たとえば、ひらがなの「あ」のコード・ポイントU+3204は、UTF-16のリトル・エンディアンでは 42 30 、UTF-32では 42 30 00 00の順になる。
エンディアンが関係するのはマルチ・バイトのバイト順であり、1バイト内のビットの順番は常に 7 6 5 4 3 2 1 0 である。
短期連載
第1回 文字コードについて ~その歴史と役割
第2回 IBM iの日本語環境 ~EBCDIC編
第3回 IBM iの日本語環境 ~Unicode編
著者
三神 雅弘氏
日本アイ・ビー・エム株式会社
システム事業本部 サーバー・システム事業部
コグニティブ・システムズ事業統括
シニアITスペシャリスト
1989年、日本IBM入社。AS/ 400のテクニカル・サポートを担当。日本IBM システムズ・エンジニアリングへの出向を経て、2004年よりテックライン、2016年よりビジネス・パートナー向けテクニカル・サポート、2018年よりIBM iブランド業務を兼任している。

[i Magazine 2020 Autumn(2020年10月)掲載]







